Boom, we’re back! You used bag of words text mining to make the frequent words plot. You can tell you used bag of words and not semantic parsing because you didn’t make a plot with only proper...
Boom, we’re back! You used bag of words text mining to make the frequent words plot. You can tell you used bag of words and not semantic parsing because you didn’t make a plot with only proper nouns. The function didn’t care about word type.
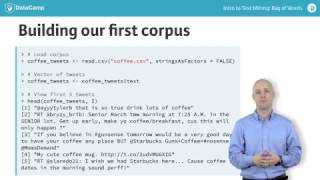
In this section we are going to build our first corpus from 1000 tweets mentioning coffee. A corpus is a collection of documents. In this case, you use read.csv to bring in the file and create coffee_tweets from the text column.
coffee_tweets isn’t a corpus yet though. You have to specify it as your text source so the tm package can then change its class to corpus. There are many ways to specify the source or sources for your corpora. In this next section, you will build a corpus from both a vector and a data frame because they are both pretty common.